
Operations using pandas
Importing external files in jupyter notebook:
In jupyter notebook we can read and edit many types of files like excel files, csv files, html files and many more files.
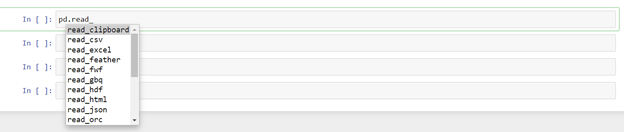
To read a file in jupyter notebook,
pd.read_csv(“file_name.csv”) #to read csv file
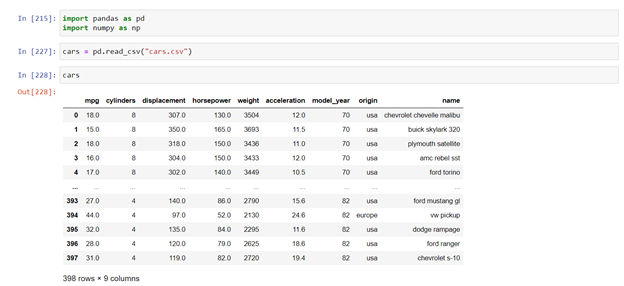
There are many operations that can be performed on the data.
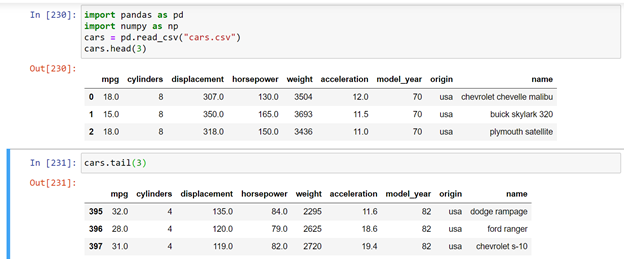
To view top few rows we have to pass
cars.head ( x ) #where x is number of rows we needed
Similarly to view botton part we have to pass
cars.tail ( x ) # where x in number of bottom rows we needed
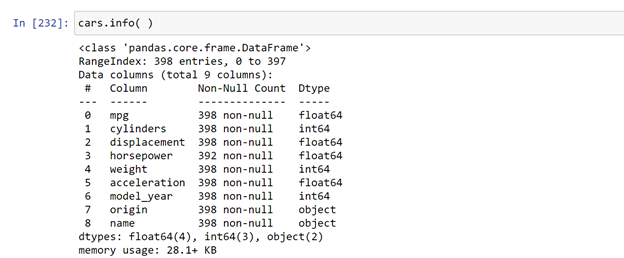
To get an overview of the imported file, pass
cars.info( )
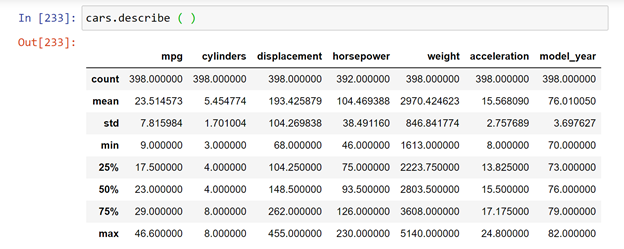
Now where there are integer values we can get all statistical data by passing
cars.describe ( )
Here we only get the integer values and charcters get dropped, what if we also needed charcters then pass
cars.describe ( include = “O” ) # here O stands for objects, In python objects means either a string or mixed data type
We can also check any presence of null values in the importes file.
Let us access all the column names by passing
cars.columns

Some main functions :
Unique values in a data frame:
When it comes to data manipulation there will be thousands of similar values in a data, sometimes it becomes important to extract unique values in a particular column. Here we will be working with a data set names “cars”, which has a collection of data of cars.
Let us see the number of unique cars present in the imported data set.

There are 300 unique cars in the data set. Let us check the car name which is repeated most.
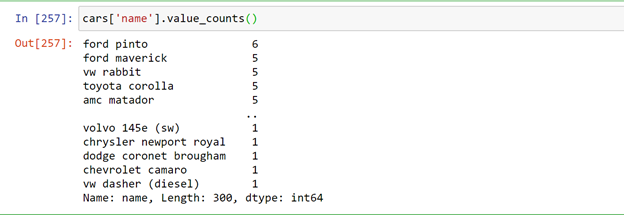
value_counts( ) gives the count of each car, but now we need only top 5 repeated cars.
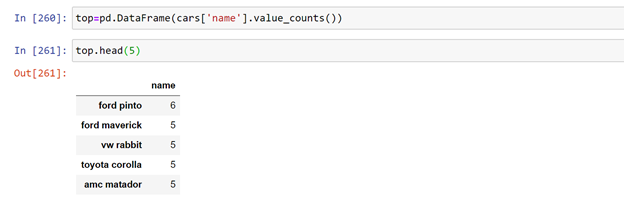
Here we have created another dataframe by passing the previous function in it and then called the head part of the new dataframe.