Introduction to pandas
Pandas is a very powerful tool for data scientist , this tool is used to manipulate data like filling the missing values , filtering , sorting and many other operations on CSV , EXCEL , HTML and other files. It is an open source tool built top on numpy library. This is also know as python version of excel.
Things we would learn about pandas.
Ø Series
Ø DataFrame
Ø Manipulating missing data
Ø Groupby
Ø Merging data
Ø Joining data
Ø Concatenating data
Ø Several operations using pandas
Series:
This is a form of collection of data just like an one dimensional array, there is one difference that series posses indexing for each element.
| One dimensional array | Series |
| Array ( [ 10,20,30,40 ] ) | Series 0 10 1 20 2 30 3 40 |
From this we can get that indexing is very important in series, unless any indexing is given , Pandas assign indexing from zero and so on.
Parameters of a series:
| Parameter | Its functioning |
| data | Data for the Series |
| Index | For indexing, if not given , then automatically considers indexing from zero ( optional ) |
| datatype | Data type for the output series , if not mentioned , then this will be inferred from the data. ( optional ) |
| name | The name to be given to the series . ( optional ) |
| copy | Copy input data . ( optional ) |
> Creating a series:
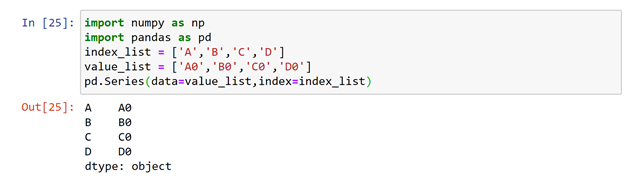
- Using a dictionary:
Once we create a dictionary, We can assign the keys as index or the values as indexing.
When a dictionary is passed through series and indexing is not assigned then automatically keys are choosen as index.

- Creating a series using scalar :
We also can create a series without giving any other form of data as input to the series unlike passing a dictionary or something else.

- Creating a series using lists:
Here in this method we have to create two lists, one for index and another for values.
Accessing data from series:
To access the data we should store the series in a variable, here we stored it in ‘a’. To access any data we have to pass the index label .
series_name [‘index_label’]

Suppose we need to access multiple values then we have to pass multiple index labels in a list.
series_name[ [ ‘index_1’,’index_2’] ]

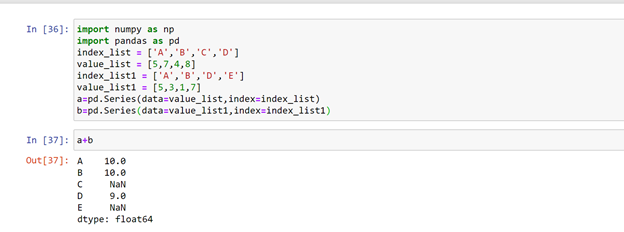
Adding two series:
When we add two series their data get added, if the index labels are same are else it gives ‘nan’ as ouput. Here two series are defined containing few common index labels and some non-common index labels.
This is similar to two dimensional array , but in two dimensional index is neither specified to rows nor columns. Here in dataFrames there are row index labels and column index labels
| Two dimensional array | DataFrame |
| ( [ [ 1,2,3,4 ] [ 3,6,4,7 ] [ 3,7,0,0 ] ] ) | 0 1 2 3 0 1 2 3 4 1 3 6 4 7 2 3 7 0 0 |
This is the basic and most important difference between two dimensional array and dataframe.
Parameter in dataframe:
| Parameter | |
| Data | This is the data we should provide |
| index | This is row indexing, if not provided it takes from zero |
| columns | This is column indexing, if not provided it takes from zero |
| copy | To copy the data , inbuilt it is saved in the form Boolean False. |
Creating a DataFrame:
A dataframe can be created using lists, Series , dictionaries or another dataframe also.

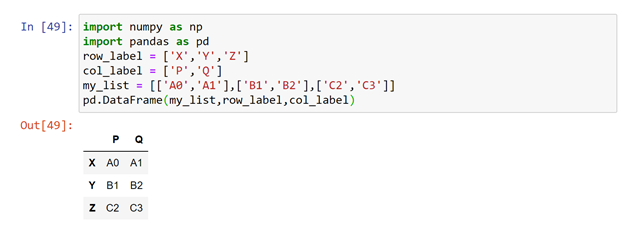
Creating data frame using list:
Here the index labels were not specified by the user, Suppose we wanted to put label names accordingly we can do that. By considering the parameters of dataframe we can give the row labels and column labels as input to the pd.dataframe.
Accessing a column :
A complete column can be accessed in two ways.
Dataframe_name.column_label
DataFrame_name[‘col_label’]
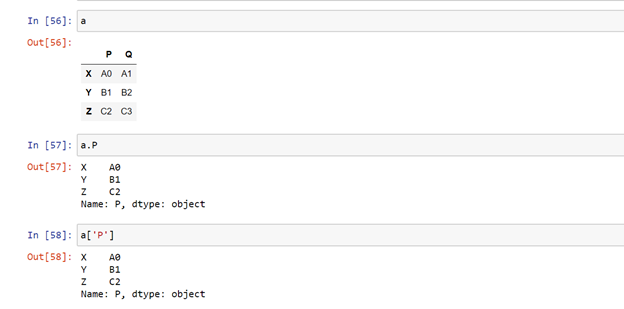
To access multiple columns
Pass the column names in a list and we can access them.
Dataframe_name [ [‘col1’,’col2’] ]

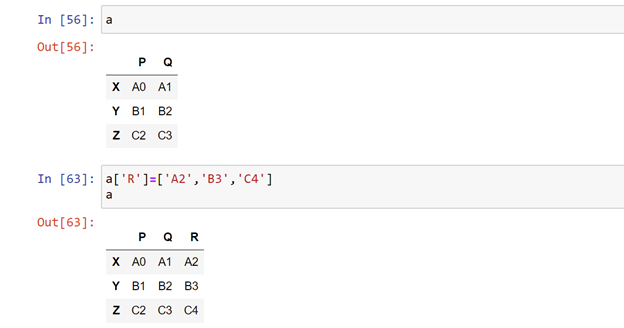
Defining a new column:
To define a new column
Dataframe_name[‘new_col’] = [‘data’]
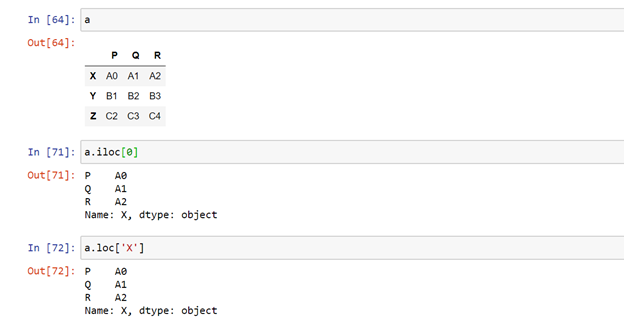
Accessing a row in the dataframe:
There are two ways to access a complete row in a dataframe. Row can be accessed using the row label or row index number.
Dataframe_name.loc[ ‘ row_name’ ] #label based indexing
Dataframe_name.iloc [ ‘row_number’ ] #position based indexing
Few important operations:
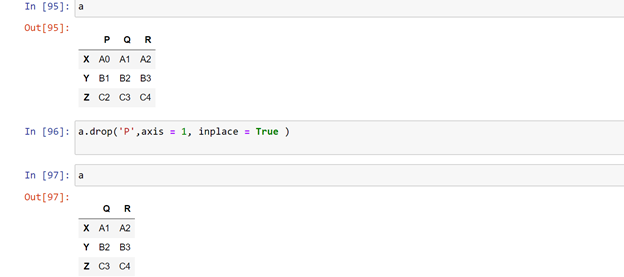
drop( ) : To drop a row or column , this function can be used. But this function doesn’t remove the row or column completely , it just removes in the present code.

Once we call the dataframe again , the dropped row is retained. This is something good that pandas provide , so sometimes accidently the data doesn’t get removed. To remove permanently, we have to use a parameter inplace = True

This function removes only rows until unless another parameter axis is called.
axis= 0 for row operations
axis = 1 for column operations